‘Talks’
Elements of Scale: Composing and Scaling Data Platforms
Tuesday, April 28th, 2015
This post is the transcript from a talk, of the same name, given at Progscon & JAX Finance 2015.
There is a video also.
As software engineers we are inevitably affected by the tools we surround ourselves with. Languages, frameworks, even processes all act to shape the software we build.
Likewise databases, which have trodden a very specific path, inevitably affect the way we treat mutability and share state in our applications.
Over the last decade we’ve explored what the world might look like had we taken a different path. Small open source projects try out different ideas. These grow. They are composed with others. The platforms that result utilise suites of tools, with each component often leveraging some fundamental hardware or systemic efficiency. The result, platforms that solve problems too unwieldy or too specific to work within any single tool.
So today’s data platforms range greatly in complexity. From simple caching layers or polyglotic persistence right through to wholly integrated data pipelines. There are many paths. They go to many different places. In some of these places at least, nice things are found.
So the aim for this talk is to explain how and why some of these popular approaches work. We’ll do this by first considering the building blocks from which they are composed. These are the intuitions we’ll need to pull together the bigger stuff later on.
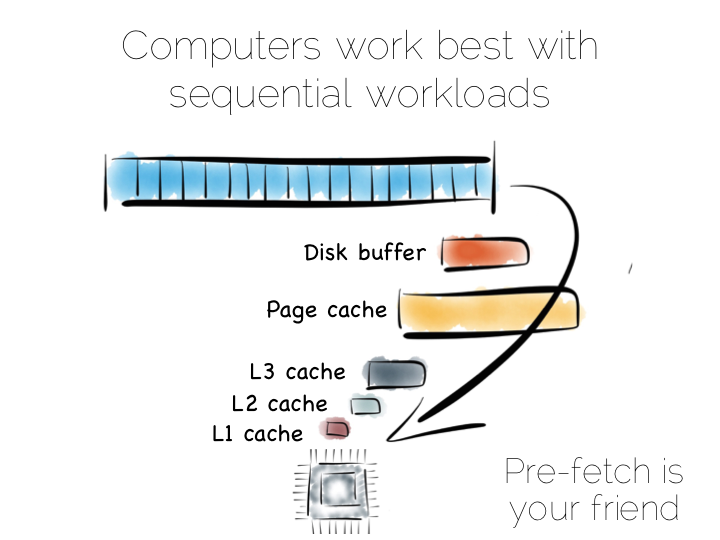
In a somewhat abstract sense, when we’re dealing with data, we’re really just arranging locality. Locality to the CPU. Locality to the other data we need. Accessing data sequentially is an important component of this. Computers are just good at sequential operations. Sequential operations can be predicted.
If you’re taking data from disk sequentially it’ll be pre-fetched into the disk buffer, the page cache and the different levels of CPU caching. This has a significant effect on performance. But it does little to help the addressing of data at random, be it in main memory, on disk or over the network. In fact pre-fetching actually hinders random workloads as the various caches and frontside bus fill with data which is unlikely to be used.
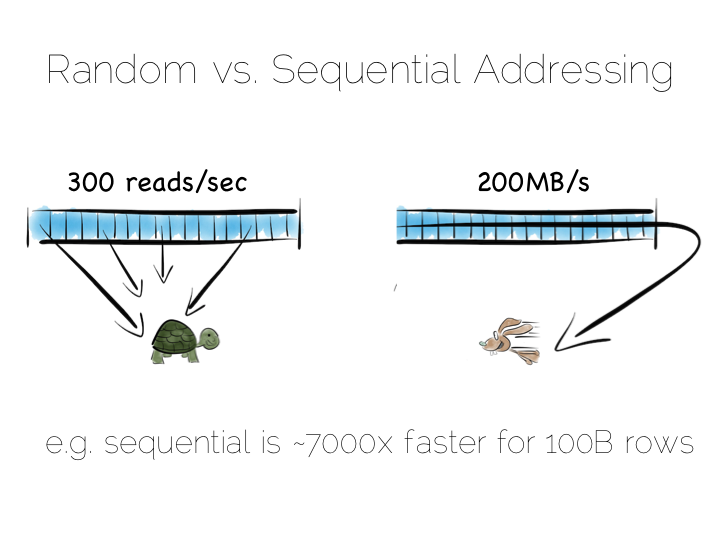
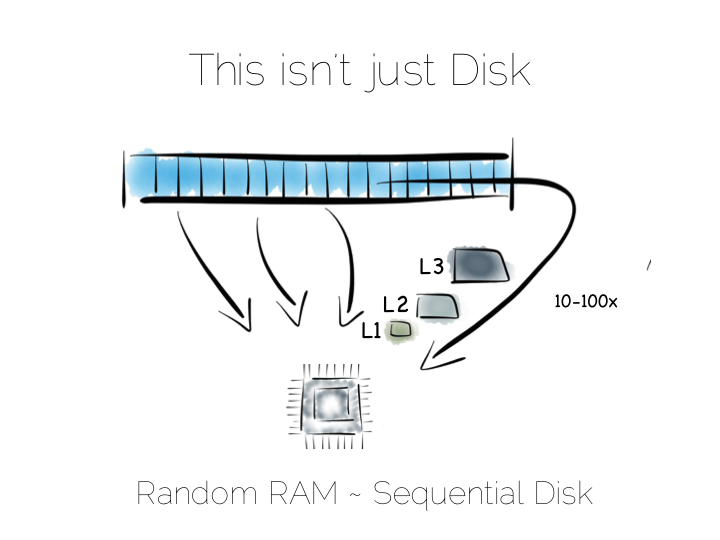
So whilst disk is somewhat renowned for its slow performance, main memory is often assumed to simply be fast. This is not as ubiquitously true as people often think. There are one to two orders of magnitude between random and sequential main memory workloads. Use a language that manages memory for you and things generally get a whole lot worse.
Streaming data sequentially from disk can actually outperform randomly addressed main memory. So disk may not always be quite the tortoise we think it is, at least not if we can arrange sequential access. SSD’s, particularly those that utilise PCIe, further complicate the picture as they demonstrate different tradeoffs, but the caching benefits of the two access patterns remain, regardless.
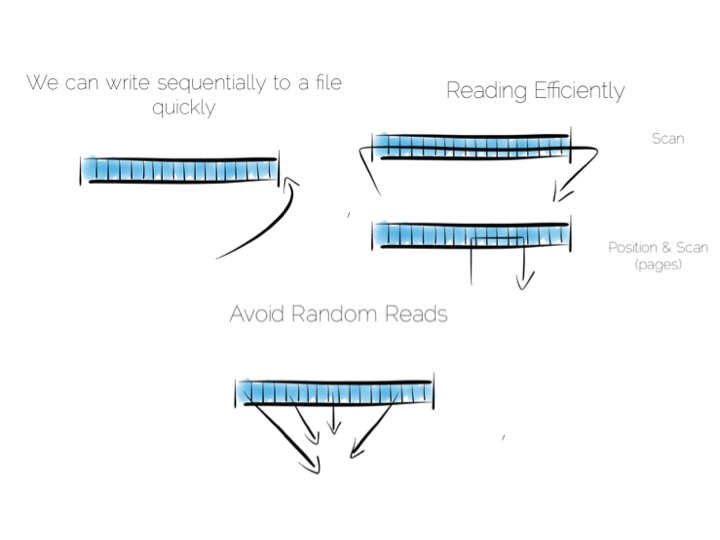
So lets imagine, as a simple thought experiment, that we want to create a very simple database. We’ll start with the basics: a file.
We want to keep writes and reads sequential, as it works well with the hardware. We can append writes to the end of the file efficiently. We can read by scanning the the file in its entirety. Any processing we wish to do can happen as the data streams through the CPU. We might filter, aggregate or even do something more complex. The world is our oyster!
So what about data that changes, updates etc?
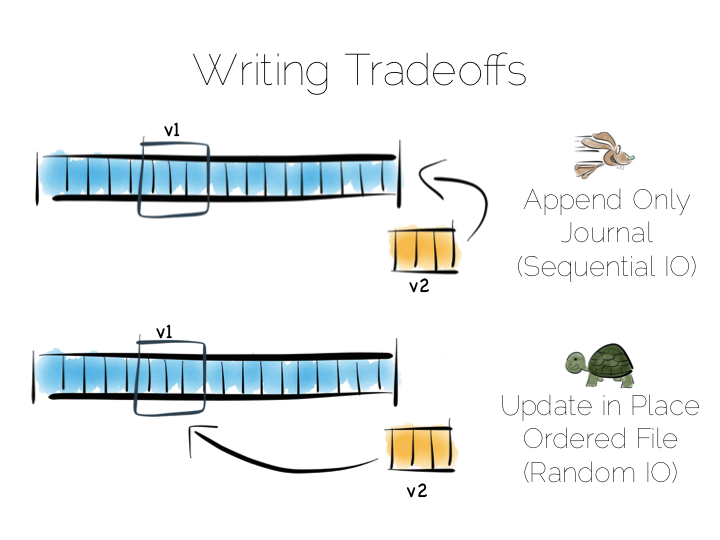
We have a couple of options. We could update the value in place. We’d need to use fixed width fields for this, but that’s ok for our little thought experiment. But update in place would mean random IO. We know that’s not good for performance.
Alternatively we could just append updates to the end of the file and deal with the superseded values when we read it back.
So we have our first tradeoff. Append to a ‘journal’ or ‘log’, and reap the benefits of sequential access. Alternatively if we use update in place we’ll be back to 300 or so writes per second, assuming we actually flush through to the underlying media.
Now in practice of course reading the file, in its entirety, can be pretty slow. We’ll only need to get into GB’s of data and the fastest disks will take seconds. This is what a database does when it ends up table scanning.
Also we often want something more specific, say customers named “bob”, so scanning the whole file would be overkill. We need an index.
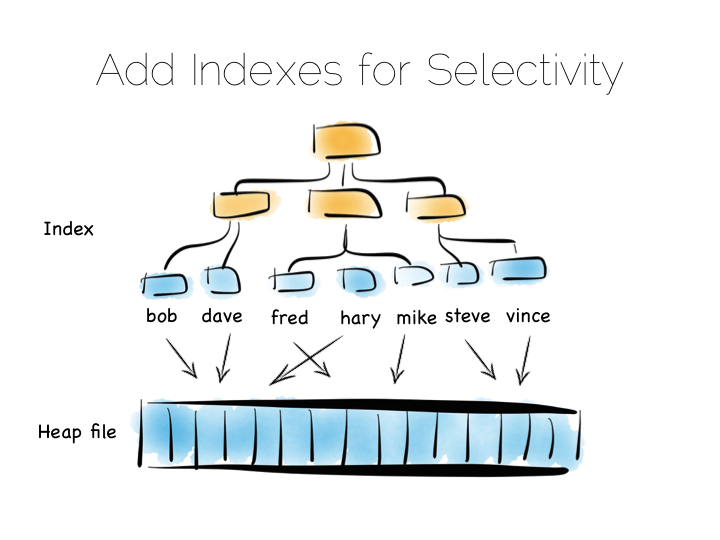
Now there are lots of different types of indexes we could use. The simplest would be an ordered array of fixed-width values, in this case customer names, held with the corresponding offsets in the heap file. The ordered array could be searched with binary search. We could also of course use some form of tree, bitmap index, hash index, term index etc. Here we’re picturing a tree.
The thing with indexes like this is that they impose an overarching structure. The values are deliberately ordered so we can access them quickly when we want to do a read. The problem with the overarching structure is that it necessitates random writes as data flows in. So our wonderful, write optimised, append only file must be augmented by writes that scatter-gun the filesystem. This is going to slow us down.
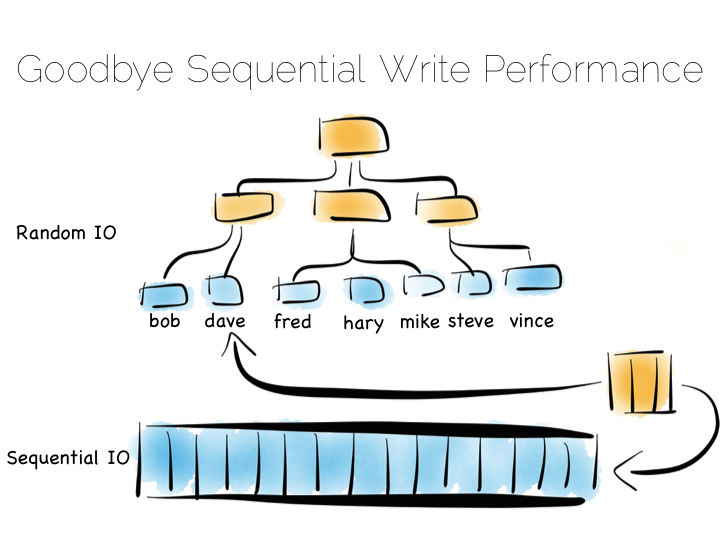
Anyone who has put lots of indexes on a database table will be familiar with this problem. If we are using a regular rotating hard drive, we might run 1,000s of times slower if we maintain disk integrity of an index in this way.
Luckily there are a few ways around this problem. Here we are going to discuss three. These represent three extremes, and they are in truth simplifications of the real world, but the concepts are useful when we consider larger compositions.
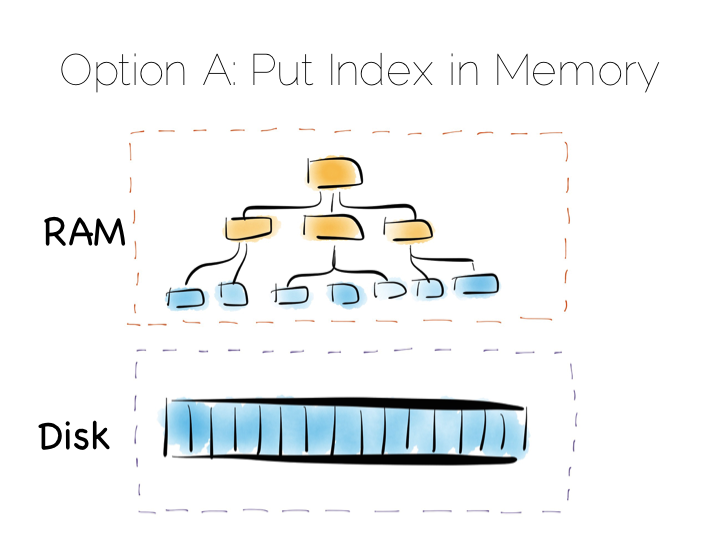
Our first option is simply to place the index in main memory. This will compartmentalise the problem of random writes to RAM. The heap file stays on disk.
This is a simple and effective solution to our random writes problem. It is also one used by many real databases. MongoDB, Cassandra, Riak and many others use this type of optimisation. Often memory mapped files are used.
However, this strategy breaks down if we have far more data than we have main memory. This is particularly noticeable where there are lots of small objects. Our index would get very large. Thus our storage becomes bounded by the amount of main memory we have available. For many tasks this is fine, but if we have very large quantities of data this can be a burden.
A popular solution is to move away from having a single ‘overarching’ index. Instead we use a collection of smaller ones.
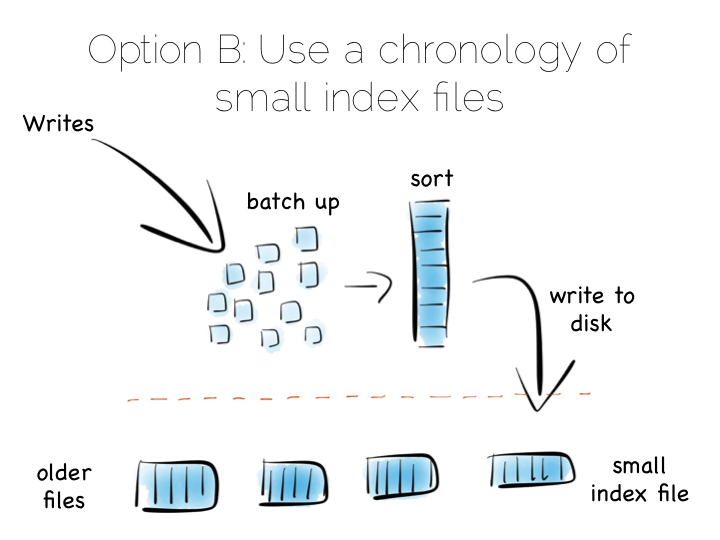
This is a simple idea. We batch up writes in main memory, as they come in. Once we have sufficient – say a few MB’s – we sort them and write them to disk as an individual mini-index. What we end up with is a chronology of small, immutable index files.
So what was the point of doing that? Our set of immutable files can be streamed sequentially. This brings us back to a world of fast writes, without us needing to keep the whole index in memory. Nice!
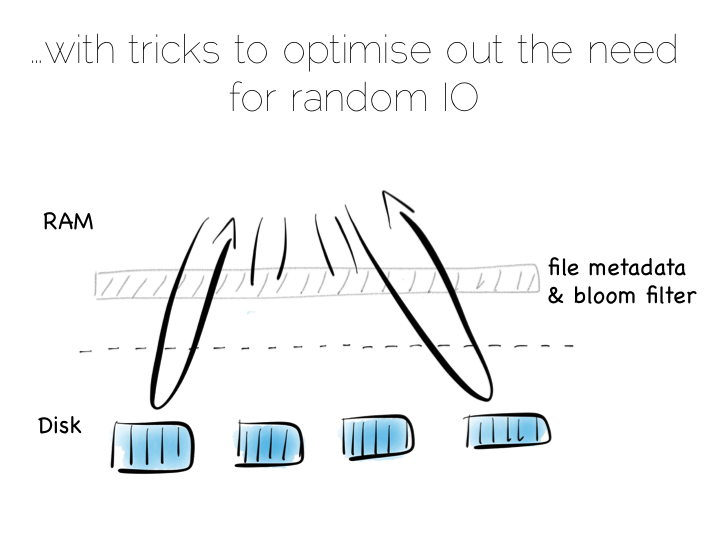
Of course there is a downside to this approach too. When we read, we have to consult the many small indexes individually. So all we have really done is shift the problem of RandomIO from writes onto reads. However this turns out to be a pretty good tradeoff in many cases. It’s easier to optimise random reads than it is to optimise random writes.
Keeping a small meta-index in memory or using a Bloom Filter provides a low-memory way of evaluating whether individual index files need to be consulted during a read operation. This gives us almost the same read performance as we’d get with a single overarching index whilst retaining fast, sequential writes.
In reality we will need to purge orphaned updates occasionally too, but that can be done with nice sequential reads and writes.
What we have created is termed a Log Structured Merge Tree. A storage approach used in a lot of big data tools such as HBase, Cassandra, Google’s BigTable and many others. It balances write and read performance with comparatively small memory overhead.

So we can get around the ‘random-write penalty’ by storing our indexes in memory or, alternatively, using a write-optimised index structure like LSM. There is a third approach though. Pure brute force.
Think back to our original example of the file. We could read it in its entirety. This gave us many options in terms of how we go about processing the data within it. The brute force approach is simply to hold data by column rather than by row. This approach is termed Columnar or Column Oriented.
(It should be noted that there is an unfortunate nomenclature clash between true column stores and those that follow the Big Table pattern. Whilst they share some similarities, in practice they are quite different. It is wise to consider them as different things.)
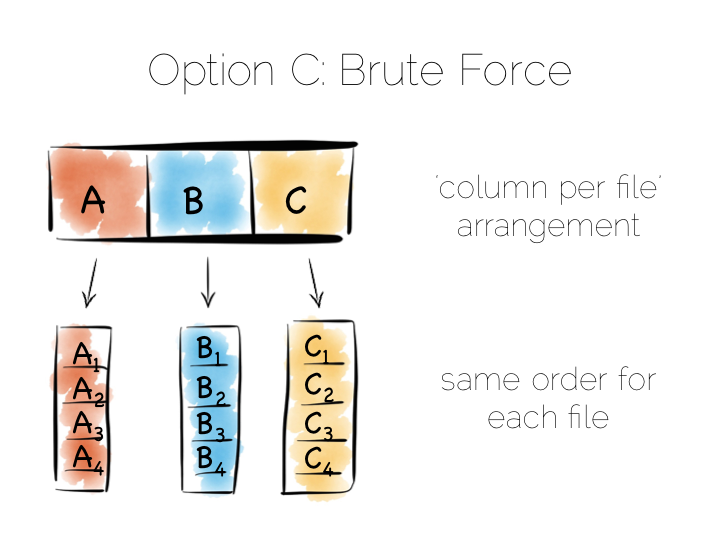
Column Orientation is another simple idea. Instead of storing data as a set of rows, appended to a single file, we split each row by column. We then store each column in a separate file. When we read we only read the columns we need.
We keep the order of the files the same, so row N has the same position (offset) in each column file. This is important because we will need to read multiple columns to service a single query, all at the same time. This means ‘joining’ columns on the fly. If the columns are in the same order we can do this in a tight loop which is very cache- and cpu-efficient. Many implementations make heavy use of vectorisation to further optimise throughput for simple join and filter operations.
Writes can leverage the benefits of being append-only. The downside is that we now have many files to update, one for every column in every individual write to the database. The most common solution to this is to batch writes in a similar way to the one used in the LSM approach above. Many columnar databases also impose an overall order to the table as a whole to increase their read performance for one chosen key.
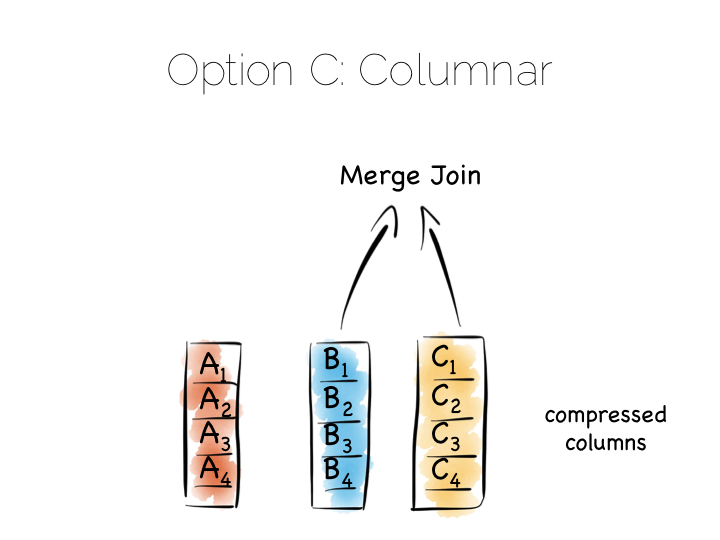
By splitting data by column we significantly reduce the amount of data that needs to be brought from disk, so long as our query operates on a subset of all columns.
In addition to this, data in a single column generally compresses well. We can take advantage of the data type of the column to do this, if we have knowledge of it. This means we can often use efficient, low cost encodings such as run-length, delta, bit-packed etc. For some encodings predicates can be used directly on the compressed stream too.
The result is a brute force approach that will work particularly well for operations that require large scans. Aggregate functions like average, max, min, group by etc are typical of this.
This is very different to using the ‘heap file & index’ approach we covered earlier. A good way to understand this is to ask yourself: what is the difference between a columnar approach like this vs a ‘heap & index’ where indexes are added to every field?
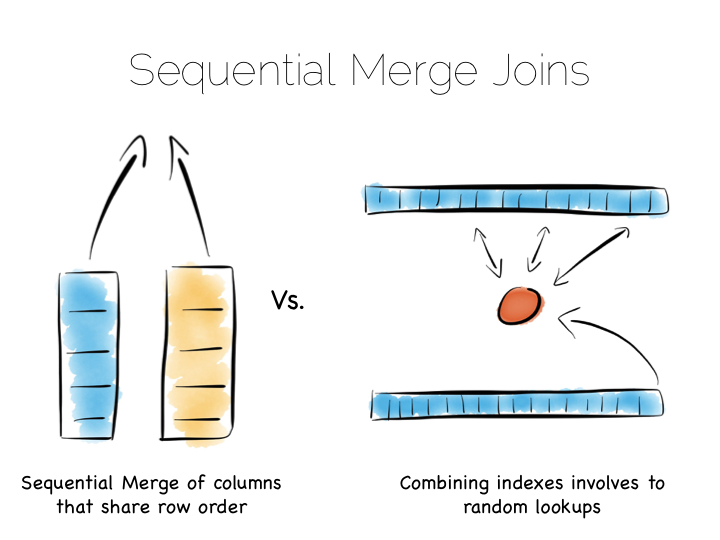
The answer to this lies in the ordering of the index files. BTrees etc will be ordered by the fields they index. Joining the data in two indexes involves a streaming operation on one side, but on the other side the index lookups have to read random positions in the second index. This is generally less efficient than joining two indexes (columns) that retain the same ordering. Again we’re leveraging sequential access.

So many of the best technologies which we may want to use as components in a data platform will leverage one of these core efficiencies to excel for a certain set of workloads.
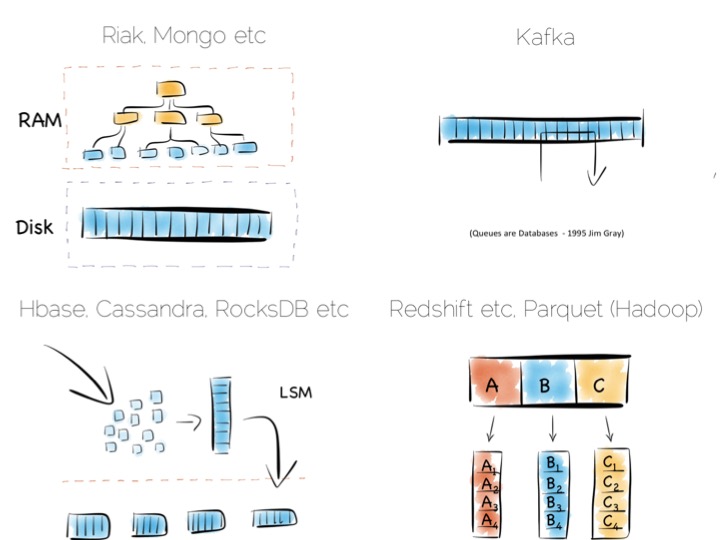
Storing indexes in memory, over a heap file, is favoured by many NoSQL stores such as Riak, Couchbase or MongoDB as well as some relational databases. It’s a simple model that works well.
Tools designed to work with larger data sets tend to take the LSM approach. This gives them fast ingestion as well as good read performance using disk based structures. HBase, Cassandra, RocksDB, LevelDB and even Mongo now support this approach.
Column-per-file engines are used heavily in MPP databases like Redshift or Vertica as well as in the Hadoop stack using Parquet. These are engines for data crunching problems that require large traversals. Aggregation is the home ground for these tools.
Other products like Kafka apply the use of a simple, hardware efficient contract to messaging. Messaging, at its simplest, is just appending to a file, or reading from a predefined offset. You read messages from an offset. You go away. You come back. You read from the offset you previously finished at. All nice sequential IO.
This is different to most message oriented middleware. Specifications like JMS and AMQP require the addition of indexes like the ones discussed above, to manage selectors and session information. This means they often end up performing more like a database than a file. Jim Gray made this point famously back in his 1995 publication Queue’s are Databases.
So all these approaches favour one tradeoff or other, often keeping things simple, and hardware sympathetic, as a means of scaling.
So we’ve covered some of the core approaches to storage engines. In truth we made some simplifications. The real world is a little more complex. But the concepts are useful nonetheless.
Scaling a data platform is more than just storage engines though. We need to consider parallelism.

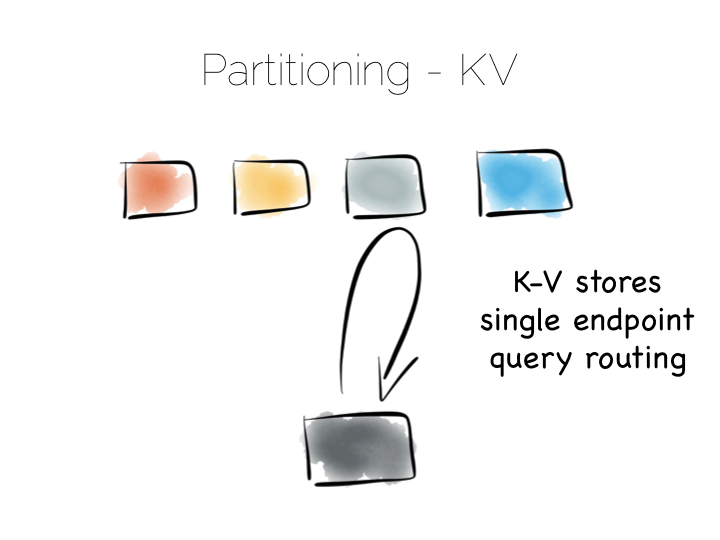
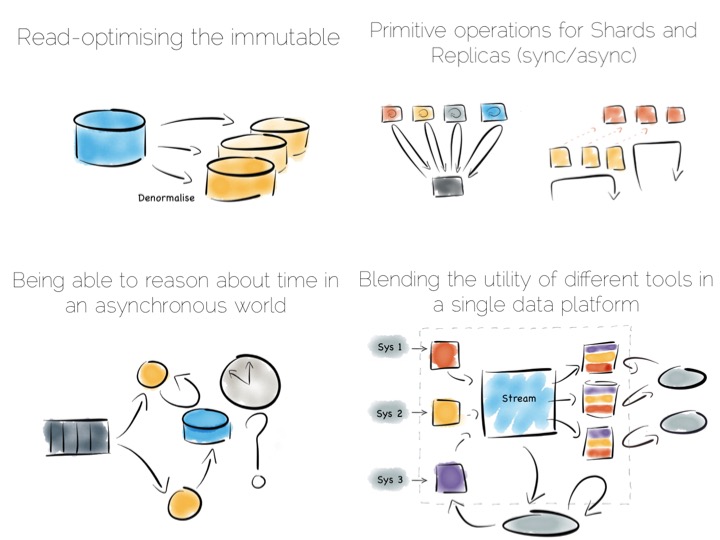
When distributing data over many machines we have two core primitives to play with: partitioning and replication. Partitioning, sometimes called sharding, works well both for random access and brute force workloads.
If a hash-based partitioning model is used the data will be spread across a number of machines using a well-known hash function. This is similar to the way a hash table works, with each bucket being held on a different machine.
The result is that any value can be read by going directly to the machine that contains the data, via the hash function. This pattern is wonderfully scalable and is the only pattern that shows linear scalability as the number of client requests increases. Requests are isolated to a single machine. Each one will be served by just a single machine in the cluster.
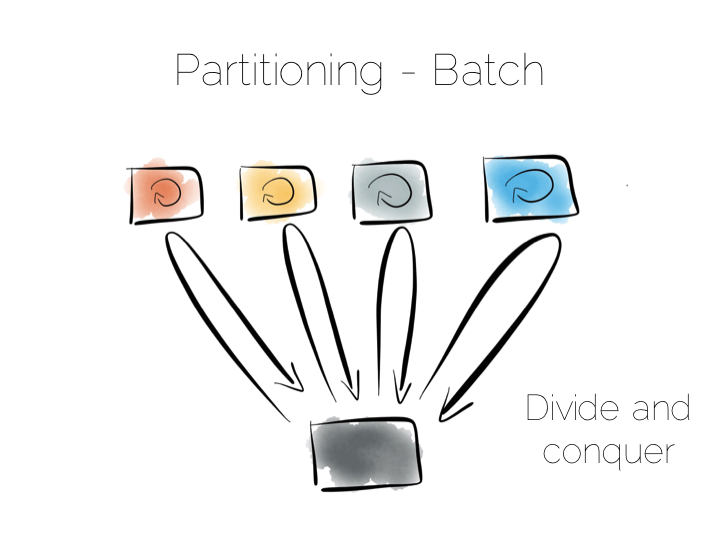
We can also use partitioning to provide parallelism over batch computations, for example aggregate functions or more complex algorithms such as those we might use for clustering or machine learning. The key difference is that we exercise all machines at the same time, in a broadcast manner. This allows us to solve a large computational problem in a much shorter time, using a divide and conquer approach.
Batch systems work well for large problems, but provide little concurrency as they tend to exhaust the resources on the cluster when they execute.
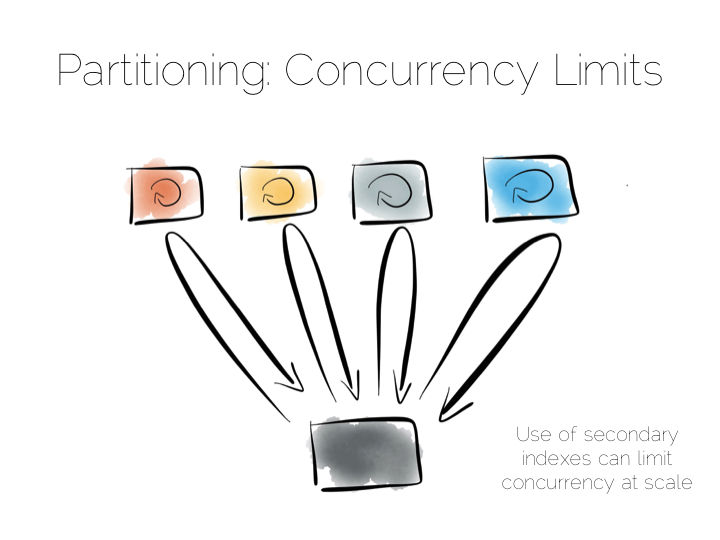
So the two extremes are pretty simple: Directed access at one end. Broadcast, divide and conquer at the other. Where we need to be careful is in the middle ground that lies between the two. A good example of this is the use of secondary indexes in NoSQL stores that span many machines.
A secondary index is an index that isn’t on the primary key. This means the data will not be partitioned by the values in the index. Directed routing via a hash function is no longer an option. We have to broadcast requests to all machines. This limits concurrency. Every node must be involved in every query.
For this reason many key value stores have resisted the temptation to add secondary indexes, despite their obvious use. HBase and Voldemort are examples of this. But many others do expose them, MongoDB, Cassandra, Riak etc. This is good as secondary indexes are useful. But it’s important to understand the effect they will have on the overall concurrency of the system.
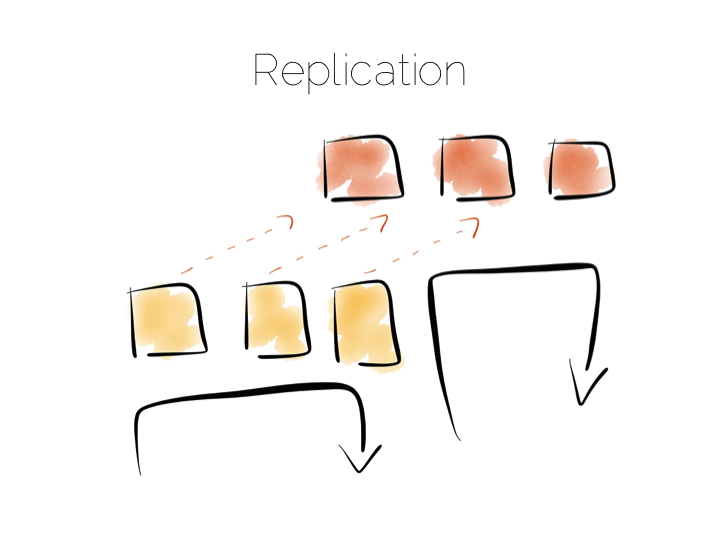
The route out of this concurrency bottleneck is replication. You’ll probably be familiar with replication either from using async slave databases or from replicated NoSQL stores like Mongo or Cassandra.
In practice replicas can be invisible (used only for recovery), read only (adding concurrency) or read-write (adding availability under network partitions). Which of these you choose will trade off against the consistency of the system. This is simply the application of CAP theorem (although cap theorem also may not be as simple as you think).
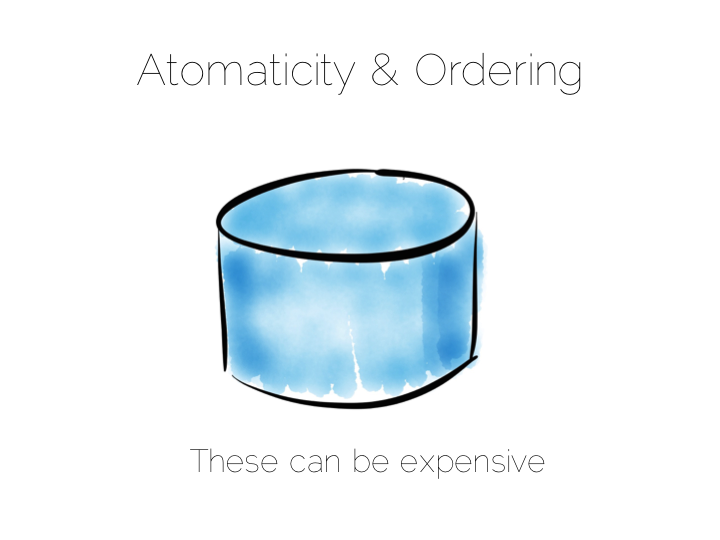
This tradeoff with consistency* brings us to an important question. When does consistency matter?
Consistency is expensive. In the database world ACID is guaranteed by linearisabilty. This is essentially ensuring that all operations appear to occur in sequential order. It turns out to be a pretty expensive thing. In fact it’s prohibitive enough that many databases don’t offer it as an isolation level at all. Those that do, rarely set it as the default.
Suffice to say that if you apply strong consistency to a system that does distributed writes you’ll likely end up in tortoise territory.
(* note the term consistency has two common usages. The C in ACID and the C in CAP. They are unfortunately not the same. I’m using the CAP definition: all nodes see the same data at the same time)
The solution to this consistency problem is simple. Avoid it. If you can’t avoid it isolate it to as few writers and as few machines as possible.
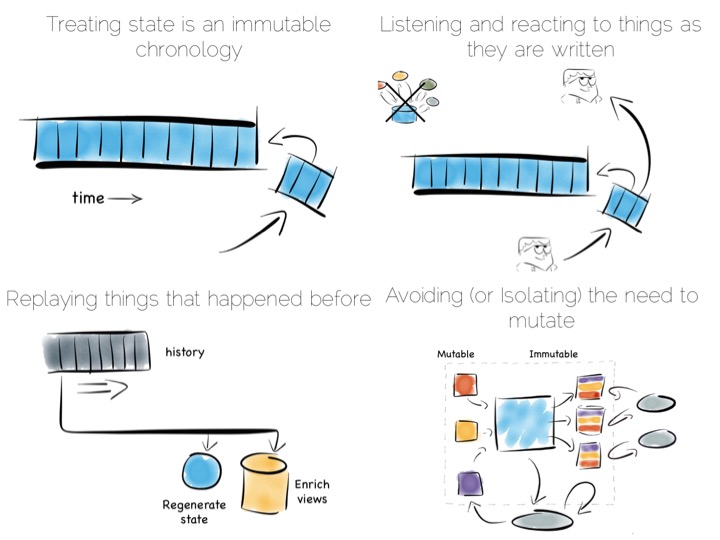
Avoiding consistency issues is often quite easy, particularly if your data is an immutable stream of facts. A set of web logs is a good example. They have no consistency concerns as they are just facts that never change.
There are other use cases which do necessitate consistency though. Transferring money between accounts is an oft used example. Non-commutative actions such as applying discount codes is another.
But often things that appear to need consistency, in a traditional sense, may not. For example if an action can be changed from a mutation to a new set of associated facts we can avoid mutable state. Consider marking a transaction as being potentially fraudulent. We could update it directly with the new field. Alternatively we could simply use a separate stream of facts that links back to the original transaction.
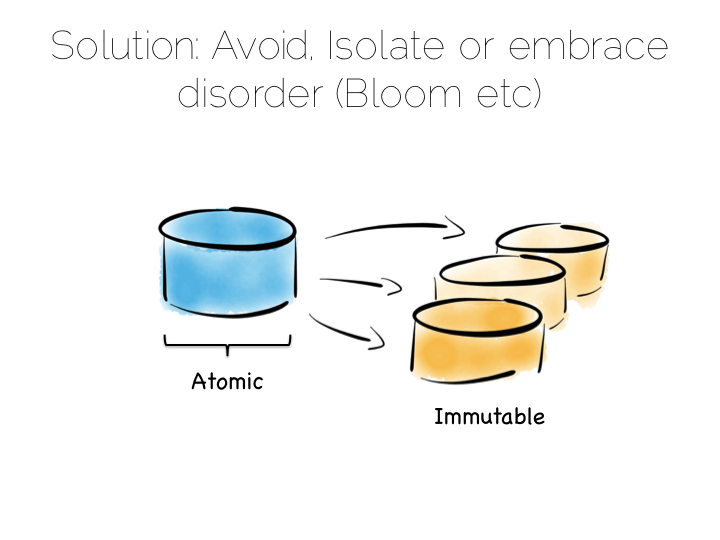
So in a data platform it’s useful to either remove the consistency requirement altogether, or at least isolate it. One way to isolate is to use the single writer principal, this gets you some of the way. Datomic is a good example of this. Another is to physically isolate the consistency requirement by splitting mutable and immutable worlds.
Approaches like Bloom/CALM extend this idea further by embracing the concept of disorder by default, imposing order only when necessary.
So those were some of the fundamental tradeoffs we need to consider. Now how to we pull these things together to build a data platform?

A typical application architecture might look something like the below. We have a set of processes which write data to a database and read it back again. This is fine for many simple workloads. Many successful applications have been built with this pattern. But we know it works less well as throughput grows. In the application space this is a problem we might tackle with message-passing, actors, load balancing etc.
The other problem is this approach treats the database as a black box. Databases are clever software. They provide a huge wealth of features. But they provide few mechanisms for scaling out of an ACID world. This is a good thing in many ways. We default to safety. But it can become an annoyance when scaling is inhibited by general guarantees which may be overkill for the requirements we have.
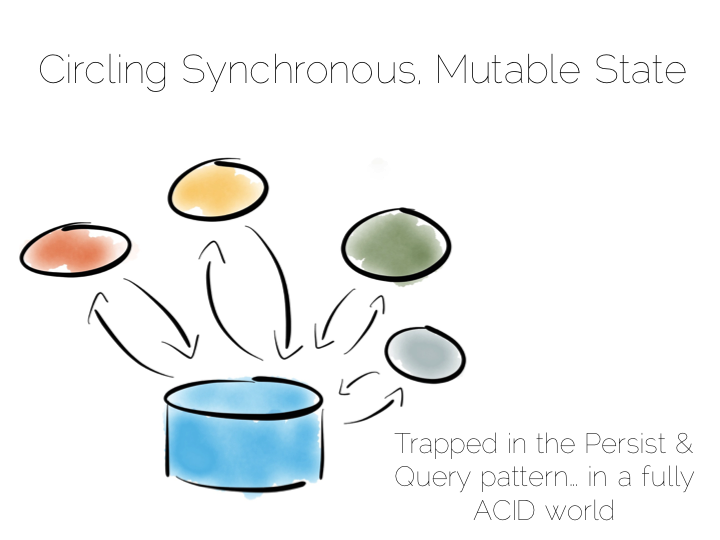
The simplest route out of this is CQRS (Command Query Responsibility Segregation).
Another very simple idea. We separate read and write workloads. Writes go into something write-optimised. Something closer to a simple journal file. Reads come from something read-optimised. There are many ways to do this, be it tools like Goldengate for relational technologies or products that integrate replication internally such as Replica Sets in MongoDB.
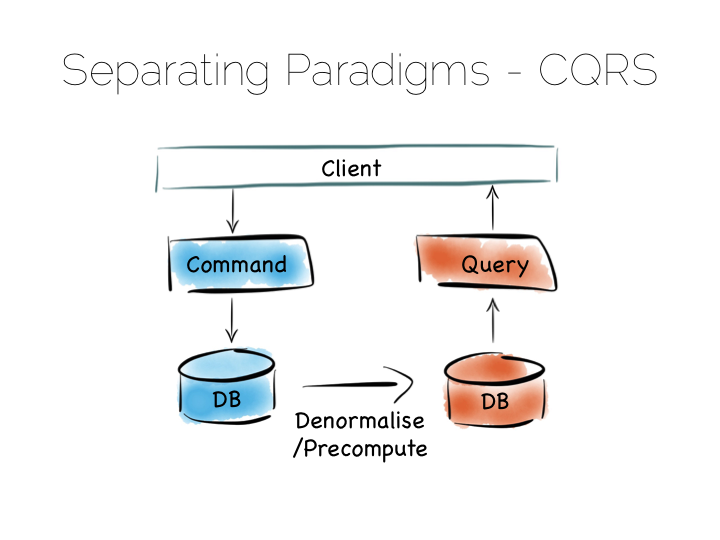
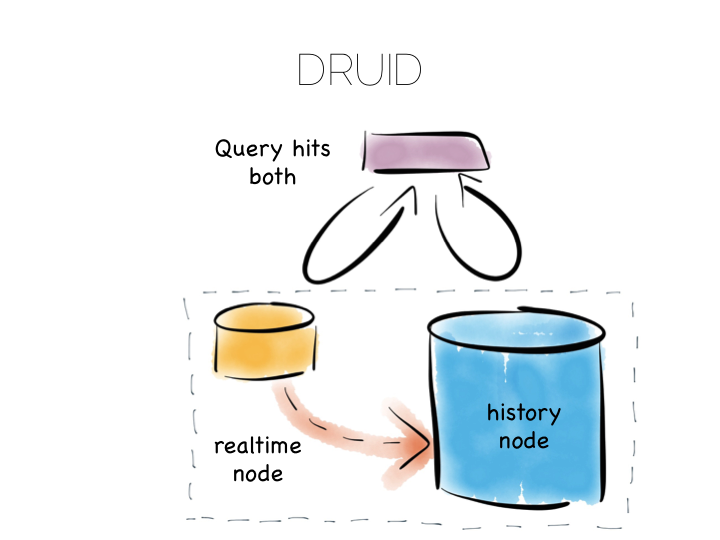
Many databases do something like this under the hood. Druid is a nice example. Druid is an open source, distributed, time-series, columnar analytics engine. Columnar storage works best if we input data in large blocks, as the data must be spread across many files. To get good write performance Druid stores recent data in a write optimised store. This is gradually ported over to the read optimised store over time.
When Druid is queried the query routes to both the write optimised and read optimised components. The results are combined (‘reduced’) and returned to the user. Druid uses time, marked on each record, to determine ordering.
Composite approaches like this provide the benefits of CQRS behind a single abstraction.
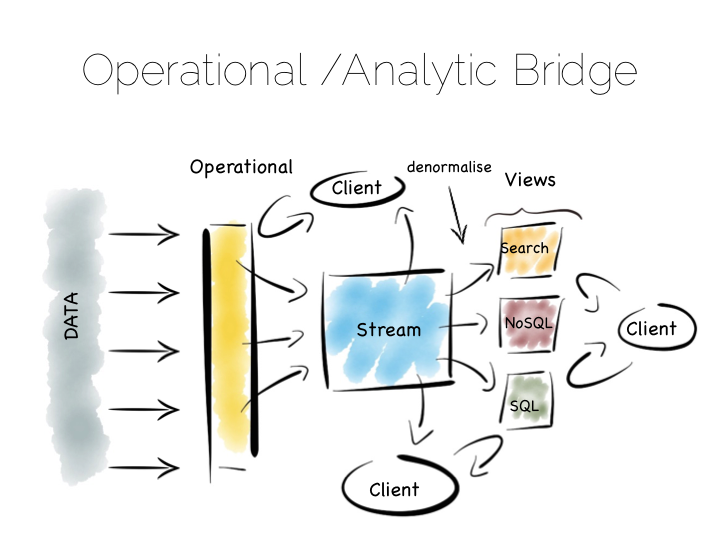
Another similar approach is to use an Operational/Analytic Bridge. Read- and write-optimised views are separated using an event stream. The stream of state is retained indefinitely, so that the async views can be recomposed and augmented at a later date by replaying.
So the front section provides for synchronous reads and writes. This can be as simple as immediately reading data that was written or as complex as supporting ACID transactions.
The back end leverages asynchronicity, and the advantages of immutable state, to scale offline processing through replication, denormalisation or even completely different storage engines. The messaging-bridge, along with joining the two, allows applications to listen to the data flowing through the platform.
As a pattern this is well suited to mid-sized deployments where there is at least a partial, unavoidable requirement for a mutable view.
If we are designing for an immutable world, it’s easier to embrace larger data sets and more complex analytics. The batch pipeline, one almost ubiquitously implemented with the Hadoop stack, is typical of this.
The beauty of the Hadoop stack comes from it’s plethora of tools. Whether you want fast read-write access, cheap storage, batch processing, high throughput messaging or tools for extracting, processing and analysing data, the Hadoop ecosystem has it all.
The batch pipeline architecture pulls data from pretty much any source, push or pull. Ingests it into HDFS then processes it to provide increasingly optimised versions of the original data. Data might be enriched, cleansed, denormalised, aggregated, moved to a read optimised format such as Parquet or loaded into a serving layer or data mart. Data can be queried and processed throughout this process.
This architecture works well for immutable data, ingested and processed in large volume. Think 100’s of TBs (although size alone isn’t a great metric). The evolution of this architecture will be slow though. Straight-through timings are often measured in hours.
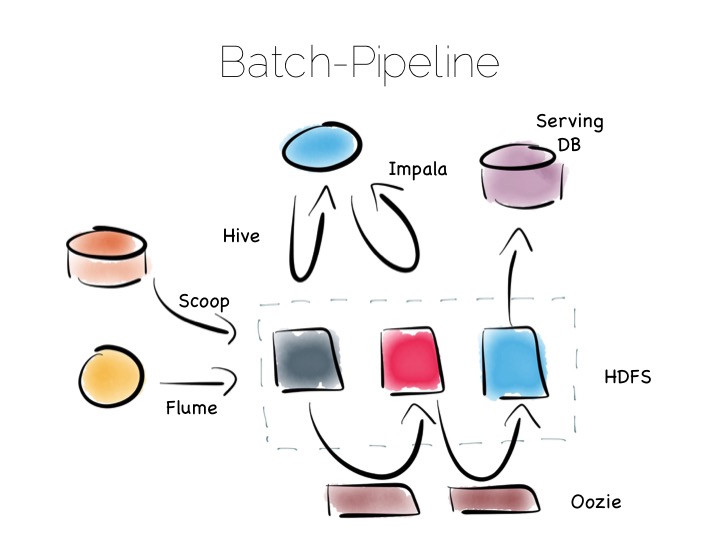
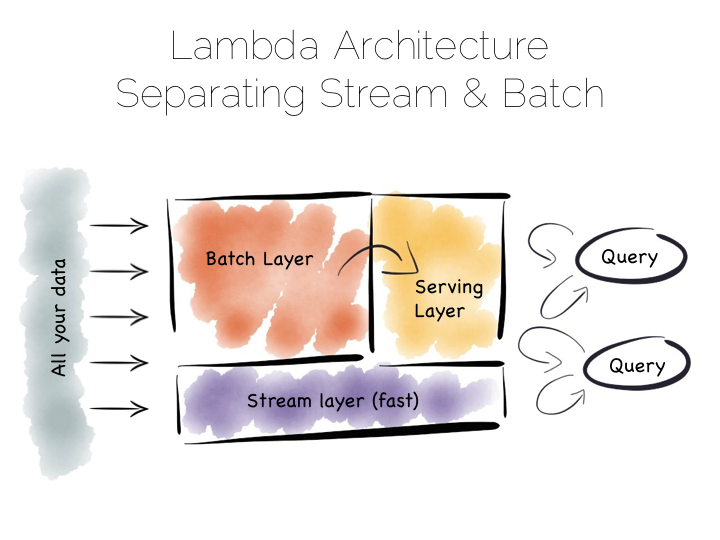
The problem with the Batch Pipeline is that we often don’t want to wait hours to get a result. A common solution is to add a streaming layer aside it. This is sometimes referred to as the Lambda Architecture.
The Lambda Architecture retains a batch pipeline, like the one above, but it circumvents it with a fast streaming layer. It’s a bit like building a bypass around a busy town. The streaming layer typically uses a streaming processing tool such as Storm or Samza.
The key insight of the Lambda Architecture is that we’re often happy to have an approximate answer quickly, but we would like an accurate answer in the end.
So the streaming layer bypasses the batch layer providing the best answers it can within a streaming window. These are written to a serving layer. Later the batch pipeline computes an accurate data and overwrites the approximation.
This is a clever way to balance accuracy with responsiveness. Some implementations of this pattern suffer if the two branches end up being dual coded in stream and batch layers. But it is often possible to simply abstract this logic into common libraries that can be reused, particularly as much of this processing is often written in external libraries such as Python or R anyway. Alternatively systems like Spark provide both stream and batch functionality in one system (although the streams in Spark are really micro-batches).
So this pattern again suits high volume data platforms, say in the 100TB range, that want to combine streams with existing, rich, batch based analytic function.
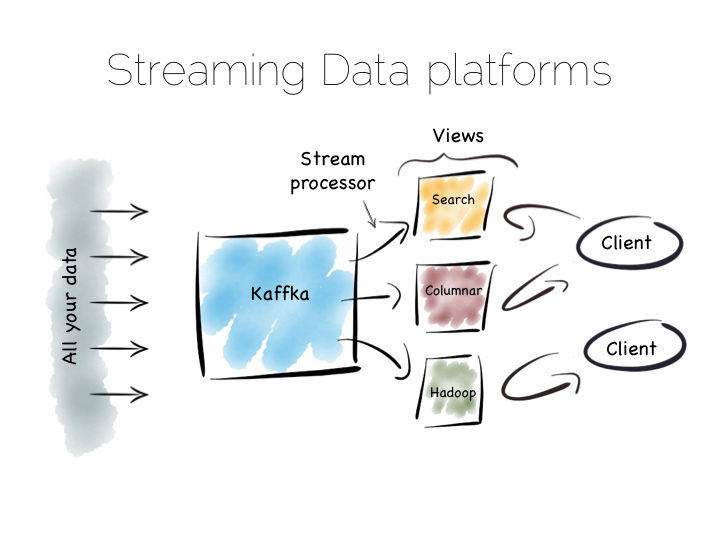
There is another approach to this problem of slow data pipelines. It’s sometimes termed the Kappa architecture. I actually thought this name was ‘tongue in cheek’ but I’m now not so sure. Whichever it is, I’m going to use the term Stream Data Platform, which is a term in use also.
Stream Data Platform’s flip the batch pattern on its head. Rather than storing data in HDFS, and refining it with incremental batch jobs, the data is stored in a scale out messaging system, or log, such as Kafka. This becomes the system of record and the stream of data is processed in real time to create a set of tertiary views, indexes, serving layers or data marts.
This is broadly similar to the streaming layer of the Lambda architecture but with the batch layer removed. Obviously the requirement for this is that the messaging layer can store and vend very large volumes of data and there is a sufficiently powerful stream processor to handle the processing.
There is no free lunch so, for hard problems, Stream Data Platform’s will likely run no faster than an equivalent batch system, but switching the default approach from ‘store and process’ to ‘stream and process’ can provide greater opportunity for faster results.
Finally, the Stream Data Platform approach can be applied to the problem of ‘application integration’. This is a thorny and difficult problem that has seen focus from big vendors such as Informatica, Tibco and Oracle for many years. For the most part results have been beneficial, but not transformative. Application integration remains a topic looking for a real workable solution.
Stream Data Platform’s provide an interesting potential solution to this problem. They take many of the benefits of an O/A bridge – the variety of asynchronous storage formats and ability to recreate views – but leave the consistency requirement isolated in, often existing sources:
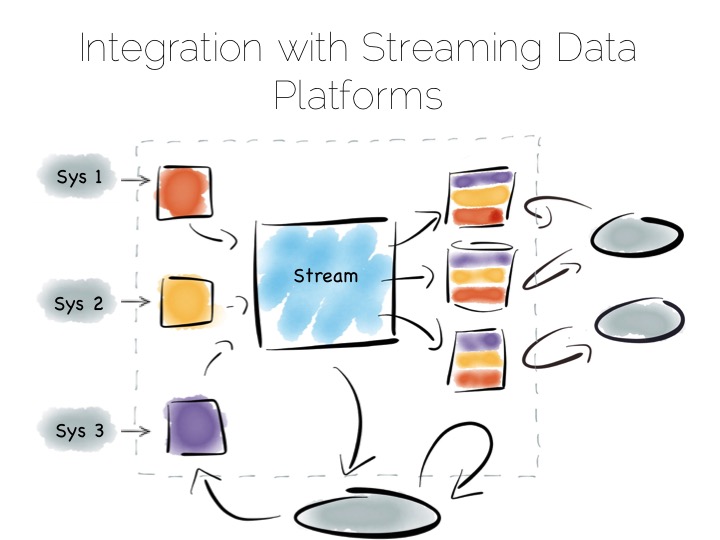
With the system of record being a log it’s easy to enforce immutability. Products like Kafka can retain enough volume and throughput, internally, to be used as a historic record. This means recovery can be a process of replaying and regenerating state, rather than constantly checkpointing.
Similarly styled approaches have been taken before in a number of large institutions with tools such as Goldengate, porting data to enterprise data warehouses or more recently data lakes. They were often thwarted by a lack of throughput in the replication layer and the complexity of managing changing schemas. It seems unlikely the first problem will continue. As for the later problem though, the jury is still out.
~
So we started with locality. With sequential addressing for both reads and writes. This dominates the tradeoffs inside the components we use. We looked at scaling these components out, leveraging primitives for both sharding and replication. Finally we rebranded consistency as a problem we should isolate in the platforms we build.
But data platforms themselves are really about balancing the sweet-spots of these individual components within a single, holistic form. Incrementally restructuring. Migrating the write-optimised to the read-optimised. Moving from the constraints of consistency to the open plains of streamed, asynchronous, immutable state.
This must be done with a few things in mind. Schemas are one. Time, the peril of the distributed, asynchronous world, is another. But these problems are manageable if carefully addressed. Certainly the future is likely to include more of these things, particularly as tooling, innovated in the big data space, percolates into platforms that address broader problems, both old and new.
~
THINGS WE LIKE
Slides from JAX London
Friday, November 1st, 2013
Similar name to the Big Data 2013 but a very different deck:
The Return of Big Iron? (Big Data 2013)
Wednesday, March 27th, 2013
Big Data & the Enterprise
Thursday, November 22nd, 2012
Slides from today’s European Trading Architecture Summit 2012 are here.
Progressive Architectures at RBS
Friday, July 6th, 2012
 Michael Stal wrote a nice article about the our Progressive Architectures talk from this year’s QCon. The video is up too.
Michael Stal wrote a nice article about the our Progressive Architectures talk from this year’s QCon. The video is up too.
Read the InfoQ article here.
Watch the QCon video here.
A big thanks to Fuzz, Mark and Ciaran for making this happen.
QCon – Where does Big Data meet Big Database
Friday, March 9th, 2012
![]()
View full QCon talk (with Video, audio and slides)
Data Storage for Extreme Use Cases
Tuesday, December 13th, 2011
This text is adapted from the guest lecture given on the Advanced Databases Course at Birkbeck. Full slides available here: http://www.slideshare.net/benstopford/advanced-databases-ben-stopford
Introduction
Comp Sci 101 normally includes something about the simplest and most efficient ways to hold and access data being via a Hashmap. Hashmaps provide rapid key based access to data – up to 20 nanoseconds for a fast implementation in Java. This speed is largely due to the structure sitting wholly in memory, allowing the computer to take advantage of its various layers of caching to optimise performance. In fact a hashmap lookup will complete in around the time it takes a light beam to travel around a typical room. That’s pretty fast!
Querying a database is a somewhat different affair. There are more steps for a start, far more codeto be executed, the OS gets involved, as will the network, and of course a disk. This brings a simple database query in at around the 20 milliseconds mark. That’s a big difference to our hashmap; around six orders of magnitude!
A comparison between these two is of course unfair, but it highlights the importance of mechanical sympathy when thinking about how we store our data.We need to be aware of the performance characteristics of each element of our systembecause each extra step costs performance. In fact there are two key factors that separate the database and the hashmap. First they are physically very different: One being a single process and one a variety of processes and a variety of steps. Secondly they are functionally different: the database provides far more functionality that the hashmap.
Modern times have brought with them a huge array of different data storage system. These systems are built using a variety of architectures, differentiated by different physical characteristics. This allows them to take different positions on the performance trade-off curve.
The onset of these new technologies has prompted some pretty vocal debate about the applicability of the traditional database architecture, characterised by row-oriented operations on a magnetic disk. Michael Stonebraker, a leading database expert, puts it quite bluntly:
“Because RDBMSs can be beaten by more than an order of magnitude on the standard OLTP benchmark, then there is no market where they are competitive. As such, they should be considered as legacy technology more than a quarter of a century in age, for which a complete redesign and re-architecting is the appropriate next step.”
The point he makes is that, if performance is truly a factor (and the data size and population are appropriate), solutions that change the architectures are more likely to win-out. In the wealth of solutions available today there are a few common themesand we’ll elaborate on these next.
Simplifying the Contract &NoSQL
One of the most recent, and pertinent, developments has been the idea of simplifying the contract. For some years data-storage has been synonymous with the implementation of ACID. However the last few years have seen a notable move away from ACID when dealing with very large data-sets where the amount of distribution required makes implementing ACID prohibitive. What’s more many applications simply don’t require these levels of guarantee. This brings us to the idea of simplifying the contract. The Internet currently contains around 5 Exabytes of data. That is a fantastically large amount, certainly in database terms. By comparison the average enterprise database is around 1 terabyte (based on research in 2009). The point is simple: the context of data management has changed and for those dealing in high-web scale data volumes simplifying the contract is absolutely mandatory.
An interesting development of the last few years has been the, rather poorly named NoSQL movement. If the name were indicative of anything it would be a (not so subtle) hint that the movers and shakers in early NoSQL technology were keen to shrug off the constraints of traditional data storage. In fact the early NoSQLstores like Voldamort and Cassandra really grew out of a simply storing data in lots of files, in an attempt to gain the scalability of simple “sharded” storage.
The idea of simplifying the contract is not limited solely to distributed datastores. Even traditional databases, residing on a single machine, have large operational overheads (with one piece of research suggesting less than 10% of instructions contribute to “useful” work).
If there is a point it is this: as you increase the level of distribution (needed to process large data sets) the practicality of implementing ACID starts to spiral out of control.
However the risks of dropping ACID, in particular embracing eventual consistency, should not be taken lightly. Drop ACID because you have to, not because you think DBAs are yesteryear weirdos that wear sandals and attach their blackberries to their belts 😉
The Three Directions of Database Progression
The are essentially three mechanisms for providing better performance over the ‘traditional’ database architecture (and I’ve tacked a fourth on the end – you’ll see why later):
- Shared disk: Several machines share a single shared disk array. Popular for mid-range data sets; but problem of disk/lock contention. Oracle RAC is a good example but there are many more in the enterprise space.
- Shared nothing – characterised by partitioning the data across different machines so that each node has complete autonomy over the data it holds; more scalable; popular for high-end data sets. Big Data era has provided a need for this architecture. But limited by performance of joins across different nodes.
- In-memory database – everything in a single address space. Query planning less important as the penalty of getting it wrong is not as crippling as in disk-based systems. The speed improvement comes from memory being at least 100 times faster than disk, as well as it being far better suited to random access c.f. TPC-H benchmark results [1]. The problem is that the address spaces is relatively small and of a fixed size (but rapidly growing over recent years from GBs to TBs). Also, there is the Durability issue of main-memory databases.
- A solution to the two problems with in-memory is to add distribution. Distributed, in-memory, shared-nothing architectures solve both the ‘one more bit’ problem as well as enabling durability. Fixed data space being solved by simply adding more machines, and durability by keeping backups elsewhere in the cluster. The downside however is that we have lost the single address space and all the advantages that go with it.
ODC – RBS’s In-Memory Datastore
(A better textual version can be found at [2] and a video covering this can be found at [3])
ODC is RBS’s in-memory data-storage solution, built on Oracle Coherence. ODC occupies an interesting position on the performance trade-off curve: Being in-memory makes it very low latency whilst being distributed, shared-nothing allows it to be high throughput. The downside is the cost of all the RAM storage.
ODC uses an interesting approach to a problem that plagues all shared-nothing data stores: the distributed join problem. This occurs when data that lives on different nodes must be joined together across the network – with the network “hops” associated with transferring the intermediary results degrading its performance.
One approach to this distributed join problem is to denormalise so that related ‘rows’ (or object graphs in our case) are always bound together. There is no need to bind them across the network because all relations are held in one row (or object graph). This is great for reducing communication costs, but hugely increases the amount of data duplication, particularly when data is versioned. The consequence is that a lot of memory is used up (memory being something of a commodity in in-memory solutions, even today). There is an additional problem of maintaining the replicated data – more specifically the issue of needing large shared locks across the multiple replicas.
So what we really want is all the advantages of normalised data with the speed of denormalisation!
The solution to this problem has two stages:
The first is to use (or rather bastardise) a Snowflake structure (of the type typical in Data Warehouse schemas) to collocate records that have the same keys. “Fact Table” records are spread across the cluster of machines while “Dimension Table” records are replicated at all nodes. Fact tables are generally much larger than Dimension tables, which is the reason that it is reasonable to replicate them.
This is best demonstrated with a simple example: Consider you have are building an online shopping application (think Amazon). Let’s say we decide to partition (“shard”) by userId. The “facts” of the system would be your basket, orders, order delivery details etc. All facts that are specific to you (i.e. to one userId) and hence can be collocated on the same machine by using userId in the hash function that specifies where data is held in the network (the well known hashing algorithm). The “dimensions” provide the context for the “facts”. Some of this context will be user-specific – like your address – but other items would be shared across many users – like the list of products the site sells. Dimensions, for example the list of products, have keys that ‘crosscut’ the key used to partition the facts, that is to say that it is not possible to uniquely partition products so that they are collocated with orders because the keys simply don’t ‘line up’. This inability to collocate Dimensions leads us to the cross-network joins we are trying to avoid.
The solution is simple: Partition facts and Replicate Dimensions. By doing so any join is possible without the need for network “hops” (i.e. no distributed joins) because all the related records are collocated at one network node.
However there is a problem, the solution to which brings us to that second stage mentioned above. It is inevitable that all Dimensions will not play to our nice heuristic. In fact, in reality, some Dimension tables will be quite large. Because they are replicated, large dimension tables are impractical due to the total memory they will consume across the cluster.
The solution is to make use of the “Connected Replication” pattern. This simply tracks whether, at a point in time, a certain Dimension record is ‘connected’ (via some path of foreign keys) to a Fact record in the database. Put another way it tracks whether a dimension record is actually used. This ‘trick’ works because, in reality, much of the Dimension data we hold is not actually used. In fact one recent study showed that 80% of the data we hold is no longer used. By implementing a simple, recursive process that navigates the hierarchy of foreign key relationships when data is inserted we can track which dimension records are used and which are not. This ‘trick’ reduces the cost of replicated storage to around 10% of its original size and by doing so really makes the idea of replicating dimensions practical in in-memory architectures.
In conclusion:
- Traditional database architectures are inappropriate for applications that require very low latency or very high throughput.
- At one end of the scale are the huge shared-nothing architectures, favouring scalability.
- At the other end are in-memory architectures, leveraging the simplicity and speed of a single address space.
- You can blend the two approaches (as, for example, in ODC).
- ODC attacks the Distributed Join Problem in an unusual way: By balancing Replication and Partitioning we can do any join in a single step. Connected Replication adds an additional ‘twist’ that reduces the amount of data replicated by an order of magnitude, making replication in an in-memory architecture practical.
References
[1] http://www.tpc.org/tpch/results/tpch_perf_results.asp?resulttype=cluster
[3] http://www.infoq.com/presentations/ODC-Beyond-The-Data-Grid
Further Reading
An fantastic paper covering many of the issues. Strongly recommended:
- The End of An Architectural Era (It’s Time for a Complete Rewrite), M. Stonebraker et al. VLDB 2007, pp 1150-1159. At http://www.vldb.org/conf/2007/papers/industrial/p1150-stonebraker.pdf
Good blog to follow:
Related modern database technologies:
- http://www.exasol.com/en/home.html
- http://www.paraccel.com/
Related articles from me:
- http://www.benstopford.com/2009/12/06/are-databases-a-thing-of-the-past/
- http://www.benstopford.com/2009/11/24/understanding-the-shared-nothing-architecture/
- http://www.benstopford.com/2011/08/14/distributed-storage-phase-change-memory-and-the-rebirth-of-the-in-memory-database/
- http://www.benstopford.com/2011/01/27/beyond-the-data-grid-building-a-normalised-data-store-using-coherence/
An Overview of some of the best Coherence Patterns
Friday, November 4th, 2011
You can view the PDF version here
Slides for Financial Computing course @ UCL
Sunday, October 23rd, 2011
Balancing Replication and Partitioning in a Distributed Java Database @JavaOne
Wednesday, October 5th, 2011
Here are a the slides for the talk I gave at JavaOne:
Balancing Replication and Partitioning in a Distributed Java Database
This session describes the ODC, a distributed, in-memory database built in Java that holds objects in a normalized form in a way that alleviates the traditional degradation in performance associated with joins in shared-nothing architectures. The presentation describes the two patterns that lie at the core of this model. The first is an adaptation of the Star Schema model used to hold data either replicated or partitioned data, depending on whether the data is a fact or a dimension. In the second pattern, the data store tracks arcs on the object graph to ensure that only the minimum amount of data is replicated. Through these mechanisms, almost any join can be performed across the various entities stored in the grid, without the need for key shipping or iterative wire calls.
See Also
Distributing Skills Across a Continental Divide
Wednesday, March 23rd, 2011
The paper: Enabling Testing, Design and Refactoring Practices in Remote Locations was presented at the IEEE International Conference on Software Testing, Verification and Validation (ICST) in Berlin in March 2011.
All credit to Amey Dhoke, Greg Gigon, Kuldeep Singh and Amit Chhajed for putting this paper together; documenting our ideas on promoting learning practices for Distributed Teams.
Test Oriented Languages: Is it Time for a New Era?
Wednesday, February 2nd, 2011
Writing tests has, sensibly, become a big part of writing software. Compilers provide a level of type, syntactic and semantic checks.
The compiler could do more though if the language included syntactic elements for state based assertions, so long as they could be compartmentalised to small, verifiable units.
This paper suggests using static analysis, in a post compilation phase, to validate declarative assertions that are built into the language syntax either through extensions or existing utilities such as annotations. This makes assertions terser, easier to read and allows their execution in statically isolated units. Execution time is minimised due to the short scope of the test and automated stubbing (in what are denoted Seams).
Using Java as an example, this paper looks to turn something like this:
@Test
public shouldBuildFoundationsWithBricksAndCement(){
Digger digger = mock(Digger.class);
CementMixer mixer = mock(CementMixer.class);
Foreman foreman = mock(Foreman.class);
Cement cement = mock(Cement.class);
BrickLayer layer = mock(BrickLayer.class);
Foundation foundation = mock(Foundation.class);
when(mixer.mix()).thenReturn(cement);
when(digger.dig()).thenReturn(foundation);
when(cement.isSolid()).thenReturn(Boolean.FALSE);
when(foreman.getLayer()).thenReturn(layer);
ConstructionSite site = new ConstructionSite(digger, mixer, foreman);
assertTrue(site.buildFoundation(new Bricks(101)))
}
into something like this:
shouldBuildFoundationsWithBricksAndCement(){
Seam:
cement.isSolid() returns false;
bricks.size returns 100;
AssertTrue:
new ConstructionSite().buildFoundation(..);
}
OR
@Test (bricks.size = 100 ,assert = "buildFoundation false")
@Test (bricks.size = 5, assert = "buildFoundation true")
@Test (bricks.size = 100, cement.isSolid true @Assert: buildFoundation false)
boolean buildFoundation(Bricks bricks){
Cement cement = mixer.mix();
Foundation foundation = digger.dig();
BrickLayer layer = foreman.getLayer();
if(!cement.isSolid() && bricks.size()> 100){
Posts posts = layer.lay(bricks, cement);
foundation.fill(posts);
return true;
}
return false;
}
Full paper can be found here: IEEE, PDF
The paper was presented at the IEEE International Conference on Software Testing, Verification and Validation (ICST) in Berlin 2011.
Beyond the Data Grid: Coherence, Normalisation, Joins and Linear Scalability (QCon)
Thursday, January 27th, 2011
 Normalisation is, in many ways, the antithesis of typical cache design. We tend to denormalise for speed. Building a data store (rather than a cache) is a little different: Manageability, versioning, bi-temporal reconstitution become more important factors. Normalisation helps solve these problems but normalisation in distributed architectures suffers from problems of distributed joins, requiring iterative network calls.
Normalisation is, in many ways, the antithesis of typical cache design. We tend to denormalise for speed. Building a data store (rather than a cache) is a little different: Manageability, versioning, bi-temporal reconstitution become more important factors. Normalisation helps solve these problems but normalisation in distributed architectures suffers from problems of distributed joins, requiring iterative network calls.
We’ve developed a mechanism for managing normalisation based on a variant of the Star Schema model used in data warehousing. In our implementation Facts are held distributed (partitioned) in the data nodes and Dimensions are replicated throughout the query-processing nodes. To save space we track ‘used’, or as we term them ‘connected’ data, to ensure only useful objects are replicated.
This model was presented at the QCon 2011 and at the Coherence SIG.
You can find the slides here (Powerpoint – 7MB).
See Also:
Are Mocks All They Are Cracked Up To Be?
Saturday, February 6th, 2010
I noticed the below snippet in Martin Fowler in his article on the subject of Mock based testing (Mocks Aren’t Stubs)
“I’ve always been an old fashioned classic TDDer and thus far I don’t see any reason to change. I don’t see any compelling benefits for mockist TDD, and am concerned about the consequences of coupling tests to implementation.”
It’s interesting for a few reasons. Firstly, it’s unusually assertive for a writer who seems to prefer that the reader make up their own mind rather than lavishing them with his own opinions (although if fairness the paragraphs that follow this excerpt do a little backpedalling). It’s also interesting as the opinion offered is quite different to those of most Thoughtworkers I met during my time there (although I did leave some time ago now).
Anyway, I was asked to talk at a small symposium on Refactoring and Testing so I thought it’s be interesting to go through my own thoughts.
You can find a hard copy of the slides here.
A full dialog can be found at the following links:
Part (1) Why We Need Stubs
Part (2) Why We Need Interaction Testing